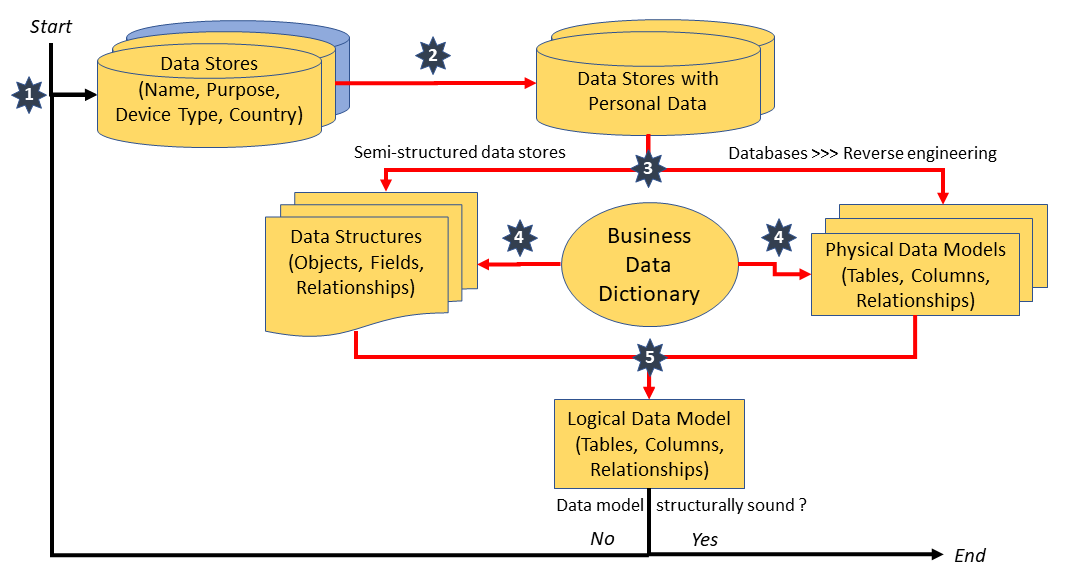
A logical data model is one of the important milestones on the road to GDPR (General Data Protection Regulation) compliance. Being the blueprint of an
organization's semantic data and the relationships among them, the logical data model
serves as the virtual hub between the existing physical data stores and the future
implementation of a GDPR-compliant data architecture.
The logical data model
even offers a GDPR-related bonus, as it teaches that being 'personal' (or non-'personal') is not an absolute characteristic of data, but depends on the
context in which these data are made available.
To illustrate the latter, let's look at an example
of a logical data model which presumably represents the business of a B2C online
retailer. This model may have been obtained as the result of the process
described in my previous post "GDPR - How to Discover and Document Personal Data" or through
any other modeling approach.
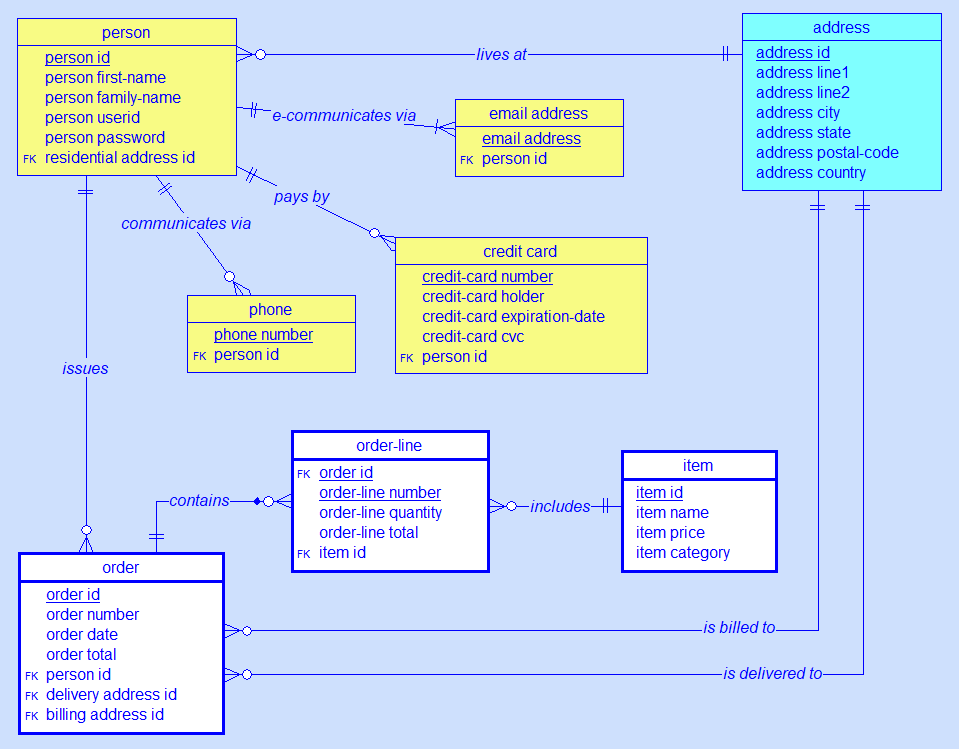 |
| Click to enlarge |
Which of these tables contain records with personal
data? As per the definition of 'personal data' imposed by the GDPR ('personal data' means any information relating to an
identified or identifiable natural person), the answer is: All of
them!
Why? Because all tables are 'related' to the table
'person', i.e. there is a path from each table to 'person' (and vice versa).
This does not mean that
all records of all tables shown here contain personal data, but those records that
can be reached through a chain of foreign-key-value to primary-key-value links (or vice versa) from a 'person id' or to a 'person id'.
In other words, the existence of relationships
(foreign keys) provides the context that categorizes records of data as
'personal' or 'non-personal'. For example, if we isolate the table 'address',
its content simply constitutes a list of addresses which may exist in public reference databases such as Google Maps and therefore cannot be considered to contain personal data. But in the context shown in the
above model, those records of the table 'address' that are identified by the
value of the foreign key 'residential address id' in table 'person' (or by values of the foreign keys
'delivery address id' and 'billing address id' in table 'order') become personal
data.
Still, the necessity and degree to protect personal
data may vary from table to table and from column to column. The sensitivity of
personal data must be evaluated, and the risk of processing personal data with
respect to the rights and freedoms of natural persons must be
assessed. Sensitivity and processing risk for each personal data element in
isolation, but more importantly for their combination and in context will influence
the physical design of data stores including measures of encrypting, pseudonymizing
and anonymizing personal data to achieve GDPR compliance. But that will be subject to another
post...