Enterprises take on a wide range of projects in the name of “Digital Transformation”. Or seek to set up programs for Data Governance, Master Data Management, Data Catalog, Business Glossary, Data Protection, Data Strategy, etc.
However, legacy systems and technical debt continue to impede many organizations' efforts. And any attempt to use such a burdened environment as a launchpad for future-proof “data” projects and programs is most likely doomed to fail.
Recommendation
The future of informational infrastructure needs to be based on a business-data-driven reference system with well-defined, distinct responsibilities. Prerequisites are
- a Chief Data Office/r as introduced earlier in my post "Pondering on Data and CDO (Chief Data Officer)"
- business division managers who are ready for additional duties, but are also flexible to give up on existing influence...
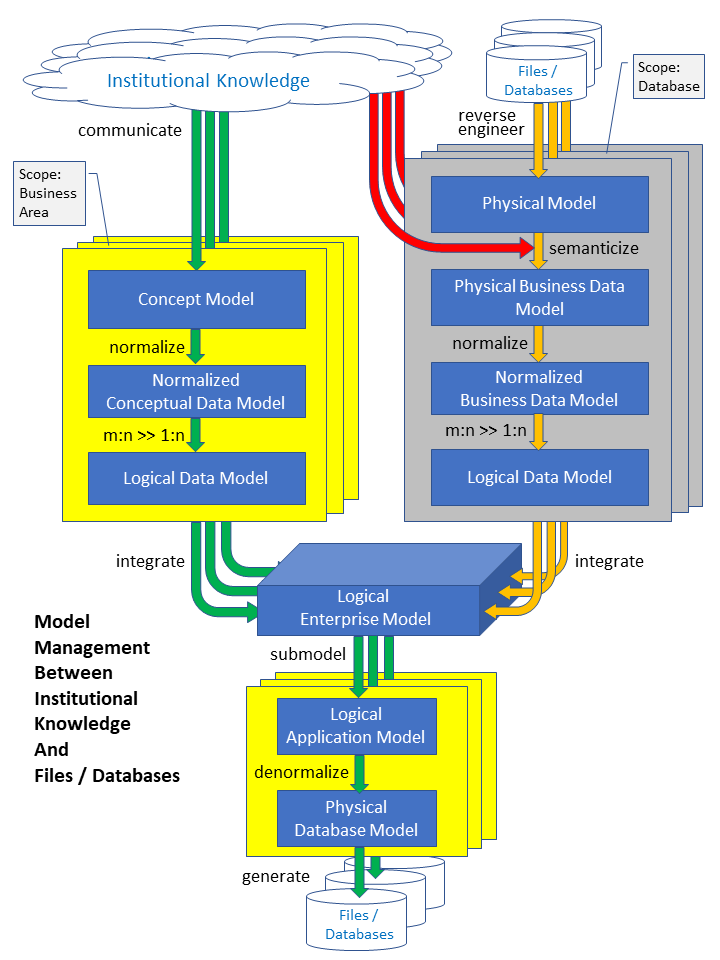
Here is the industry-agnostic approach that I propose:
- For each business unit, record the major organizational processing activities
- For each processing activity, record the major created & updated (business) data structures
- With recorded data structures, derive (business data) entities & relationships
- With entities & relationships, build the Enterprise Information Management Map (= high-level concept model)
- In the Enterprise Information Management Map, identify master entities and the relationships among them
- In the Enterprise Information Management Map, assign responsibility for modeling master entities & relationships to Chief Data Office(r) as their Data Domain Owner.
- Divide the Enterprise Information Management Map by grouping all other entities & relationships into distinct data domains based on similar processing activities and assign modeling responsibility for each data domain (= Data Domain Ownership) to exactly one business division [Note: If necessary, restructure processing activities in a way that each data domain and its creating / updating processing activities belong to only one responsible business division.]
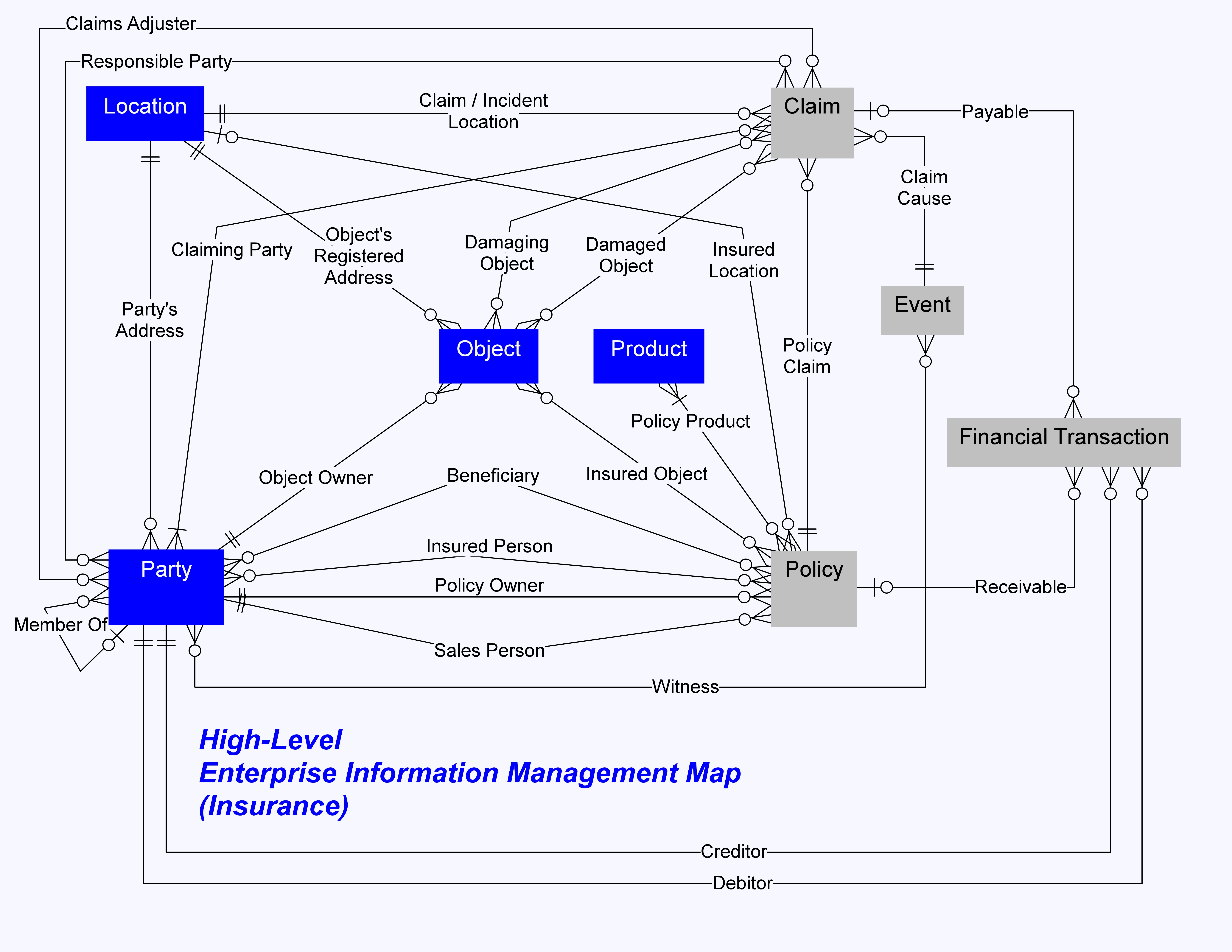 |
| Example of High-Level Concept Model in Liability Insurance [Click to Enlarge] |
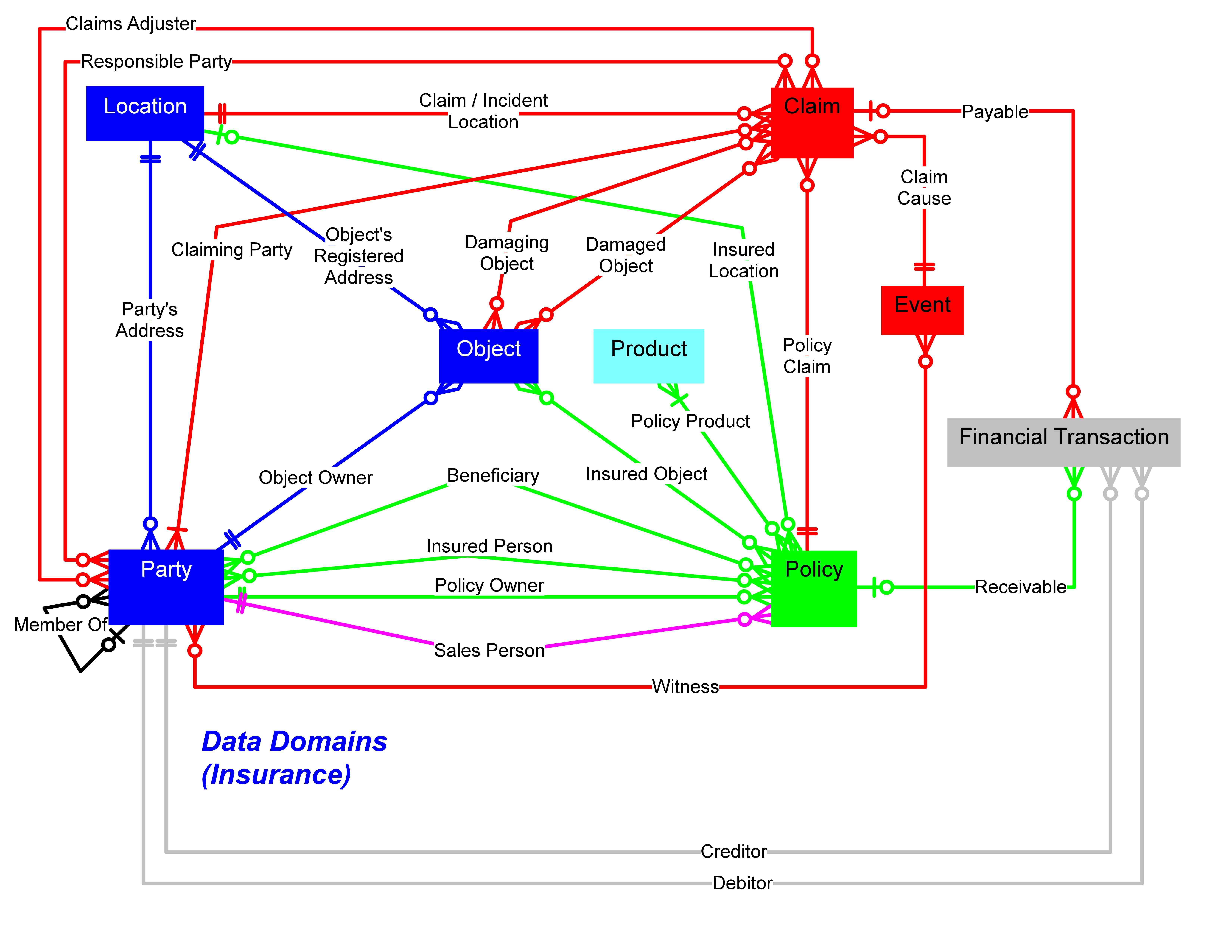 |
| Example of Data Domains in Liability Insurance [Click to Enlarge] |
Result
The above approach introduces a reference structure where each data domain within the enterprise concept model is represented by exactly one business division that is responsible to develop & maintain the related business data names, descriptions and constraints for business entities, attributes and relationships.
Outlook
In subsequent posts I will elaborate on this frame to show how to advance enterprise-beneficial data programs and projects.