Inspired by
a LinkedIn discussion here, below I respond to the two initial questions that Dylan Jones (@DylanJonesUK) posed:
Question 1: What is the value of a data management office
and why do we need one?
To state the obvious first: People with an "office job" exclusively process data (emails, telephone calls (audio data), electronic documents, paper documents, personal communication with co-workers etc.). Presuming that the employing organization is profitable, (in a simplified view) the total value of the data processed by those employees must be higher than the total of their salaries.
To see how other corporate assets are typically managed in an organization, let's look at Finances (summarizing everything that is included in a balance sheet) and People. They find their organizational representation in departments for Finance (usually headed by a CFO) and Human Resources (usually headed by a CHRO). Notwithstanding that any business department manages its particular
financial targets / budgets as well as its employees, on the corporate level the departments Finance and Human Resources fulfill a central
role which includes the following tasks (as mentioned in my post "Pondering on Data and CDO (Chief Data Officer)"):
"In their respective realm, Finance and Human Resources a.o.
- Develop corporate target scenarios and related strategies
- Ensure that the organization follows legal and regulatory obligations
- Advise business departments regarding strategic and legal aspects
- Perform tasks that are not assigned to the department level, but to the corporate level (e.g. declare taxes, report to regulatory authorities, compose the balance sheet, negotiate with the workers' union)
- Provide standard templates / procedures that operational departments can / must apply (e.g. standardize expense reports)
Since any
item of the above list is abstractly applicable to the resource Data, I suggest that medium and large enterprises implement a central unit headed by a CDO
(Chief Data Officer) who directly reports to the CEO."
More precisely, applying the above to the resource Data, the central Data Management Office's tasks include e.g.
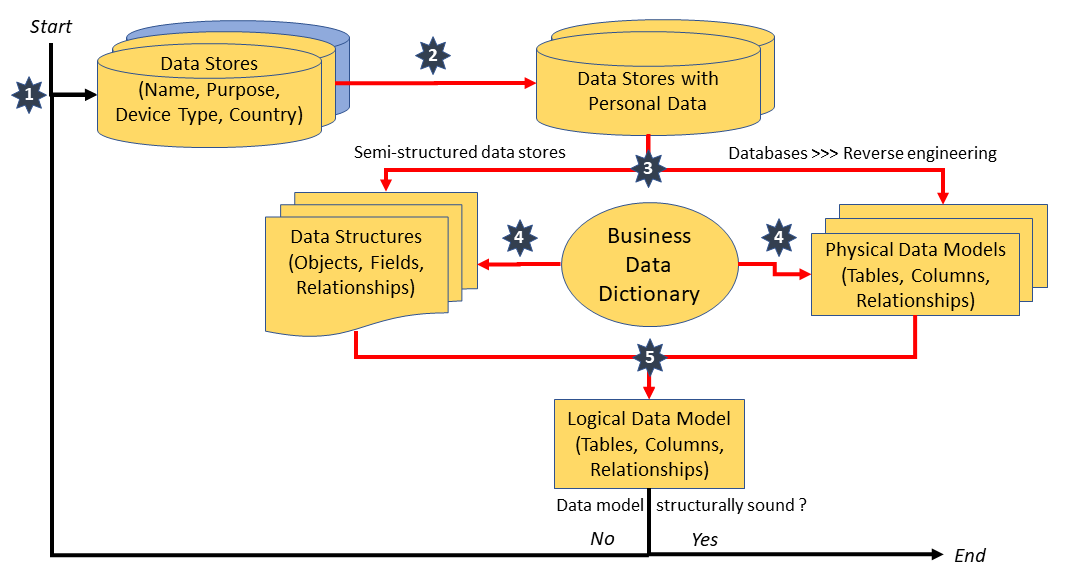
- Develop a High-Level Enterprise Information Management Map (also see my post here)
- Ensure that the organization follows worldwide-applicable regulations such as the GDPR (General Data Protection Regulation) and industry-specific regulations such as HIPAA, Solvency II, Basel III etc.
- Derive measures that respond to international, national and corporate requirements of Data Governance and advise business areas accordingly
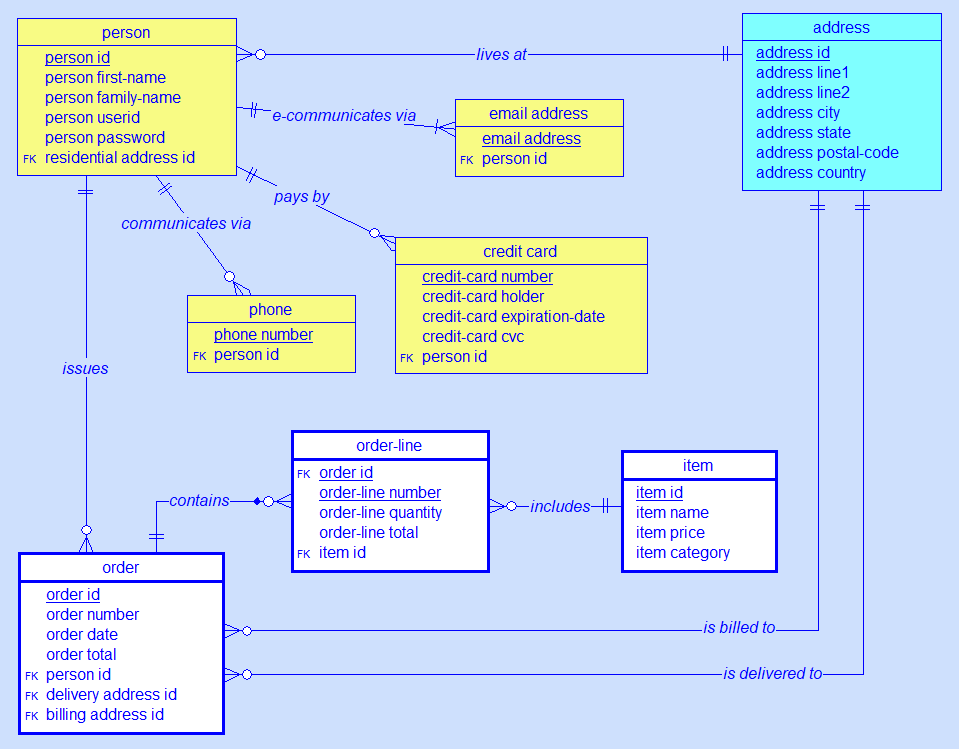
- Develop a detailed data model for the intersection of business areas (Master Data)
- Conceive standard interfaces for Master Data Management and related hubs
- Build a corporate Business Data Dictionary
Question 2: What are the pros and cons of having a
centralised DMO versus separate DMOs per business area?
Central and decentral Data Management Offices are not mutually exclusive, but should complement each other in a collaborative
climate (following the principle "Decentralize as much as possible, centralize as much as necessary"). While the obligations of the central DMO are mentioned above, each business area ought to have its separate DMO with Subject Matter Experts / Data Stewards representing their realms and performing tasks such as:
- Develop a business-area-specific data model that details the High-Level Enterprise Information Management Map
- Contribute to the corporate Business Data Dictionary
- Enforce the rules of Data Governance in their respective business areas